|
Videh Raj Nema I am a PhD student and an IndiaAI PhD fellow advised by Prof. Balaraman Ravindran at the Wadhwani School of Data Science & AI, Indian Institute of Technology, Madras. My research focuses on building an Ātmanirbhara Bhārata in STEM (a self-reliant and strong India). Presently, I work on multimodal machine learning for information synthesis. Further, my research methodology focuses on building intelligent autonomous agents that are compatible (and not necessarily indistinguishable) with humans and other intelligent agencies in a wide range of dynamic environments. Previously, I was a thesis-based MS student at the University of Alberta. I was advised by Prof. Matthew Taylor at the Intelligent Robot Learning lab, where I worked on reinforcement learning with multiple learning agents and humans integrated in a learning loop. I received the UAlberta graduate research fellowship. I completed my undergraduate in computer science and engineering from the National Institute of Technology Karnataka, Surathkal. During undergrad, I did research on reinforcement learning and received the SURF fellowship from Caltech. My research is driven towards achieving the goals of the National vision of Vikasita Bhārata@2047 and the "remaking of Bhārata". AI is a crucial technology and we need to build AI for Bhārata and build Bhārata stronger with AI in a way that is grounded in the Indian culture/values (Bhāratīyatā) and tailored to meet Bhārata's needs and interests. Concurrently, I am also interested in Indian Knowledge Systems (Bhāratīya Jñāna Paramparā) towards the effort of bringing in the "Bhāratīya" way of thought (manasā), speech (vācā), and action (karmaṇā) in STEM along with restoring the lost Indian knowledge and applying it in the present context. In this frame of reference, I am exploring the darshan shāstra: Sāṃkhya-Yoga, Nyāya-Vaiśeṣika, and Vedānta-Mīmāṃsā, so as to study STEM using the lens provided by them. |


|
ResearchMy research in undergrad and MS has mainly been on reinforcement learning. During my PhD, I am working on multimodal machine learning and omni-modal LLMs. June 13, 2026: Selected for the India AI PhD Fellowship under the India AI mission. June 1, 2026: Started internship at Sarvam AI, contributing to India's sovereign AI mission. |
|
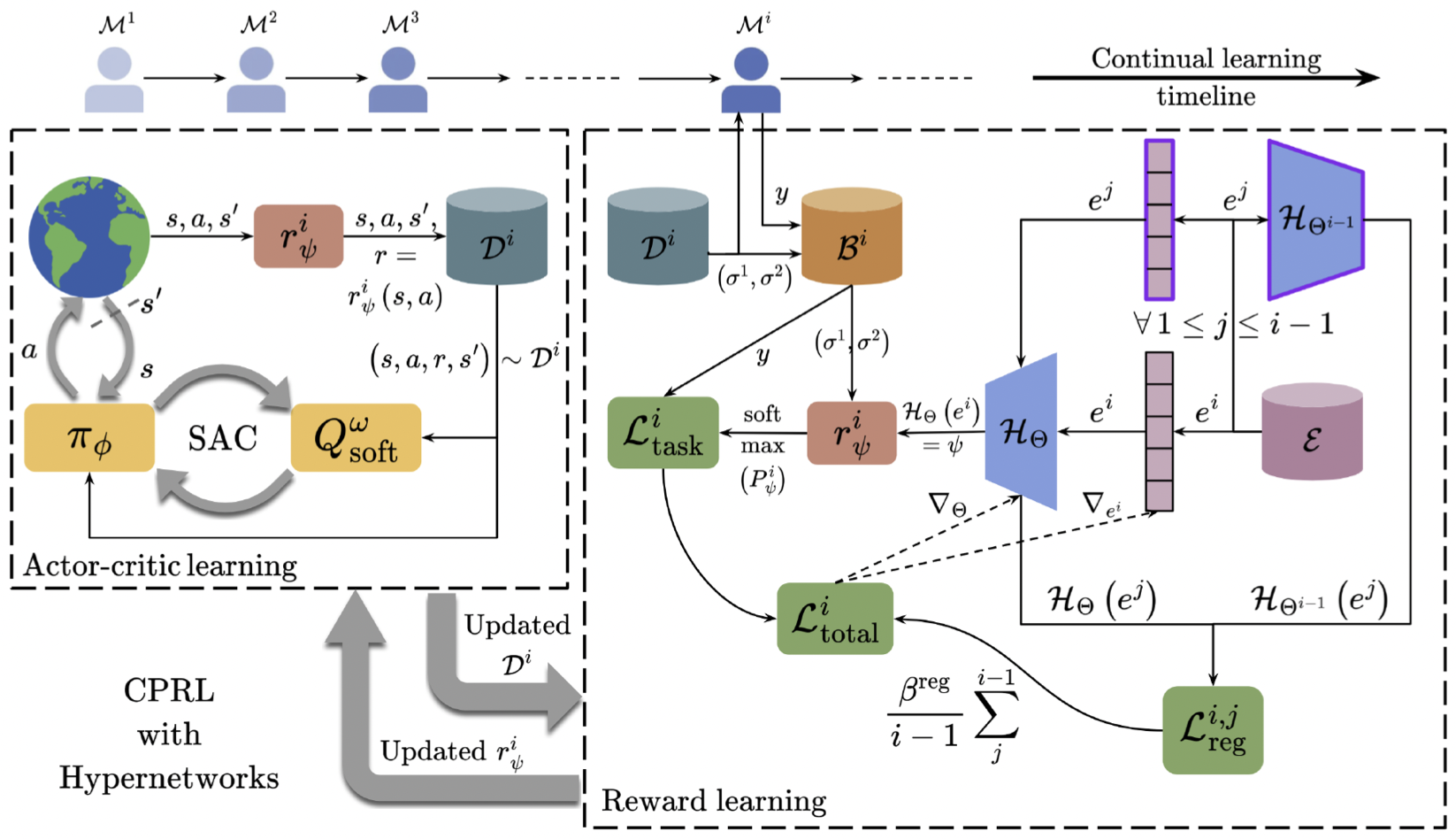
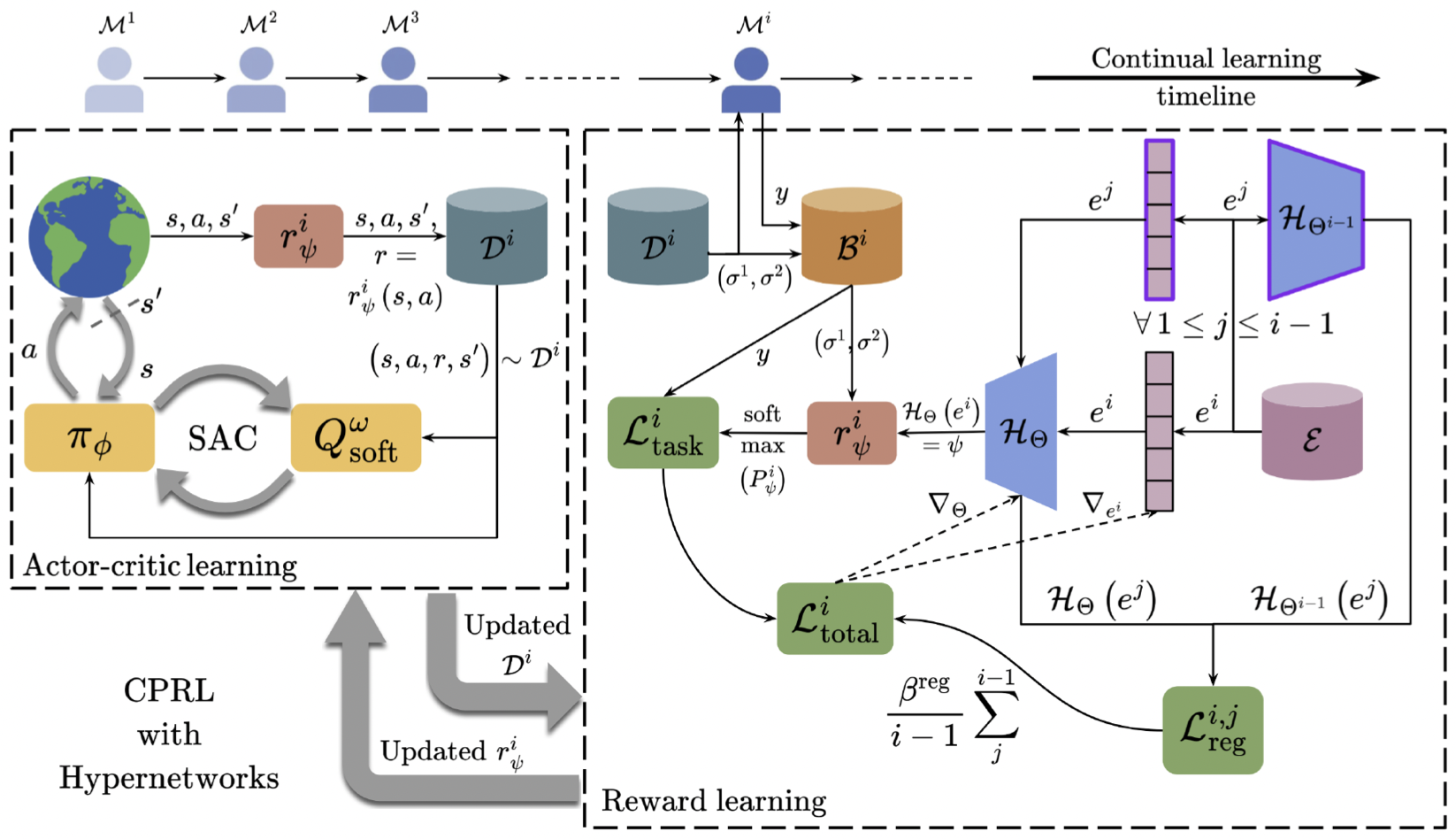
Continual Preference-based Reinforcement Learning
Videh Raj Nema, Sooraj Sathish, Calarina Muslimani, Srijita Das, Matthew Taylor Reinforcement Learning Conference: RL beyond rewards, 2026 arXiv link will be up soon A continual preference-based RL setting involving continual learning of reward functions, where the objective is to balance learning new and preserving old knowledge using task-conditioned regularized hypernetworks that learn aligned reward functions. Evaluation with simulated human feedback on five simulated robotic manipulation and locomotion domains. |
|
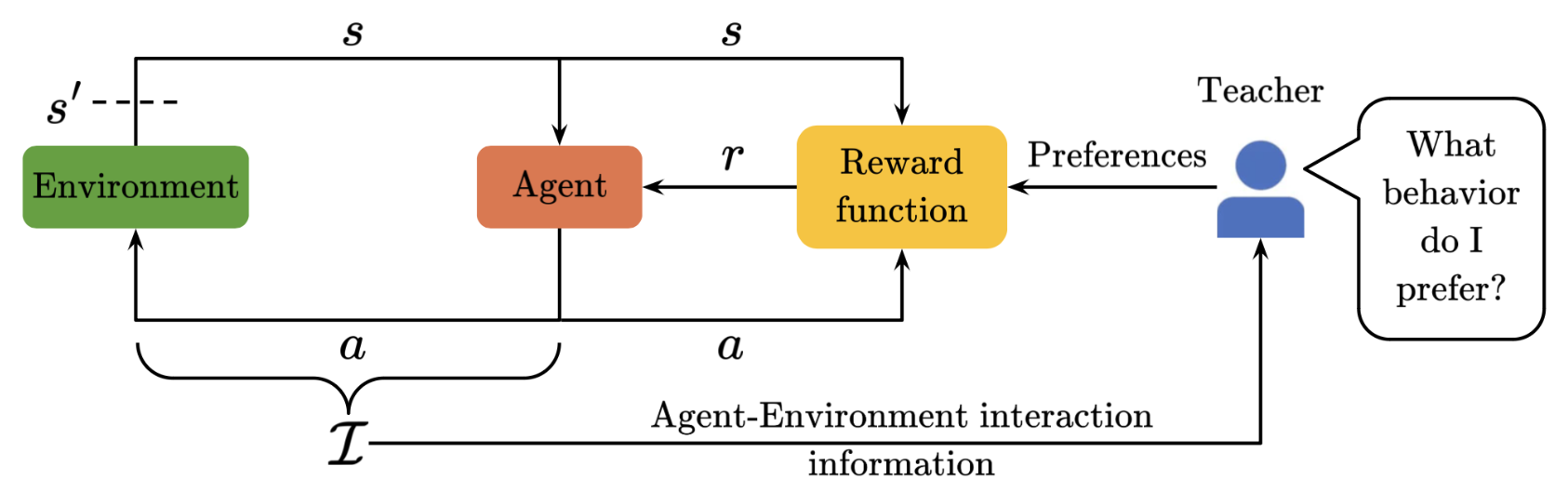
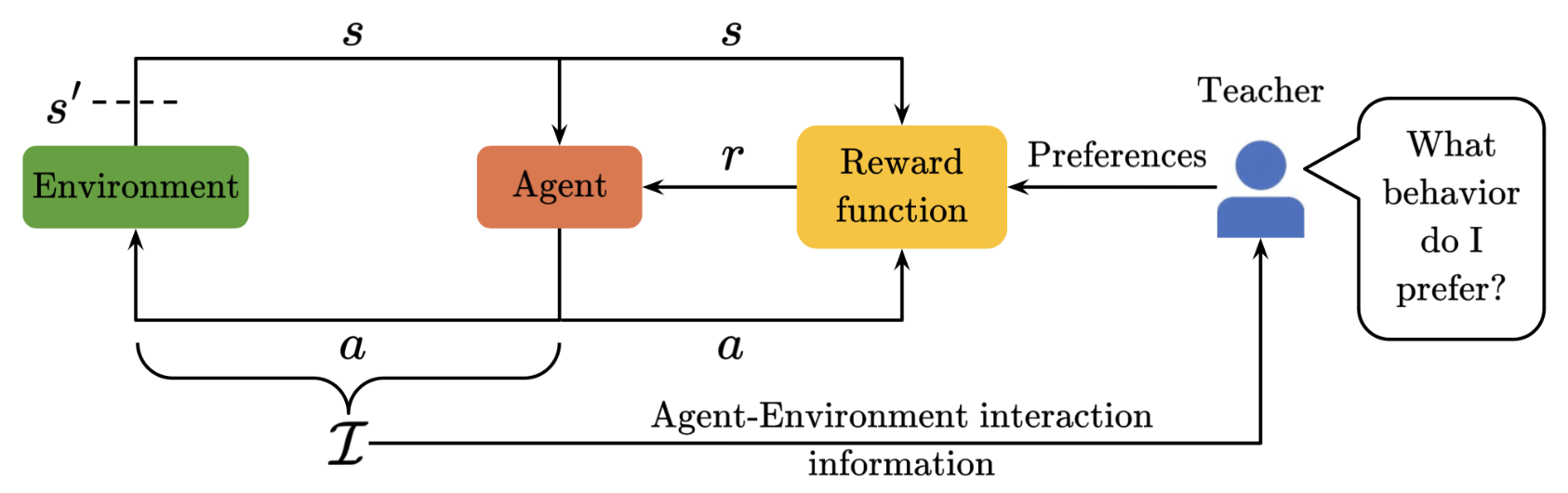
Continual Preference-based Reinforcement Learning with Hypernetworks
Videh Raj Nema University of Alberta, Spring 2025 Thesis page Nominated for the UAlberta Computing Science MS Outstanding Thesis Award Master's thesis on continual reward learning based on non-stationary teacher preferences using regularized hypernetworks. This takes a step toward human-agent interaction for the real world where the interaction is continual and the human's preferences are non-stationary. |
|
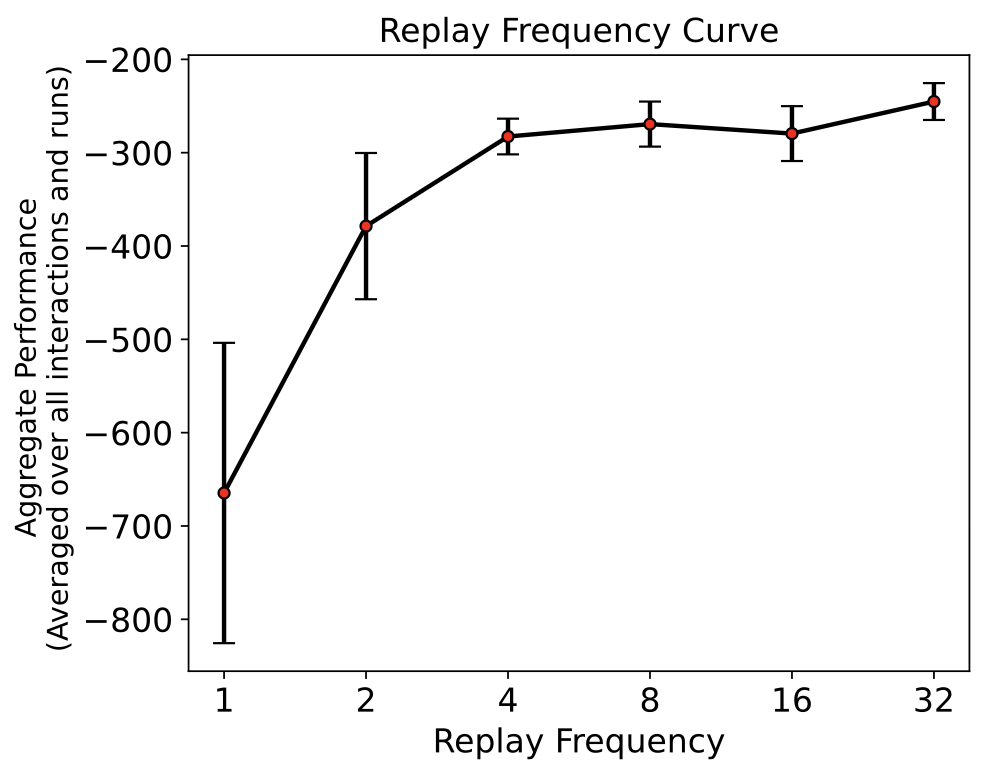
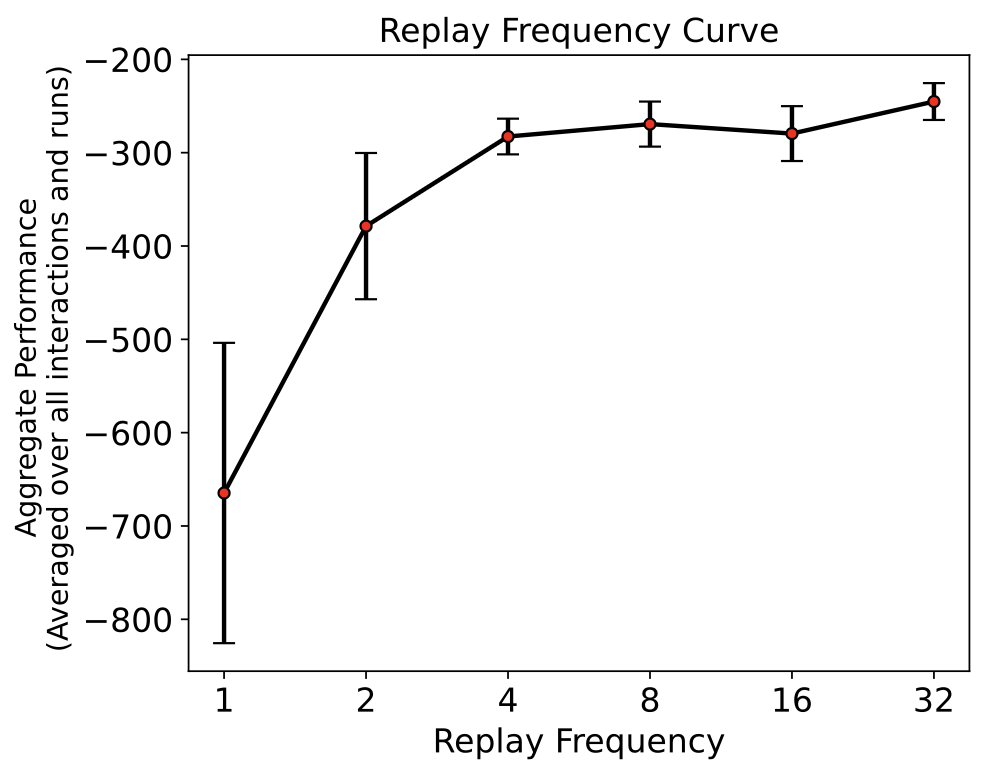
Understanding the effect of varying amounts of replay per step
Animesh Kumar Paul, Videh Raj Nema (equal contribution; work done as a part of the RL-1 course taught by Prof. Adam White at the University of Alberta) arXiv, 2023 arXiv A systematic study on the effect of varying amounts of replay per step in Deep Q-Networks (DQN). Strong empirical evidence that increasing replay improves DQN's sample efficiency, reduces the variation in its performance, and makes it more robust to change in hyperparameters. |
|
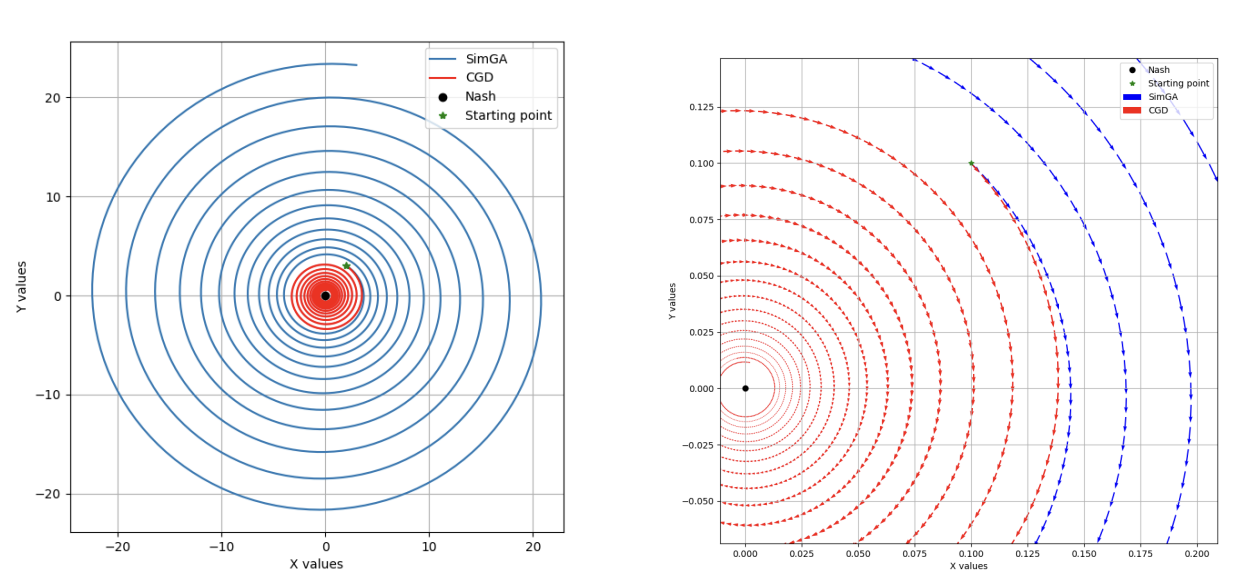
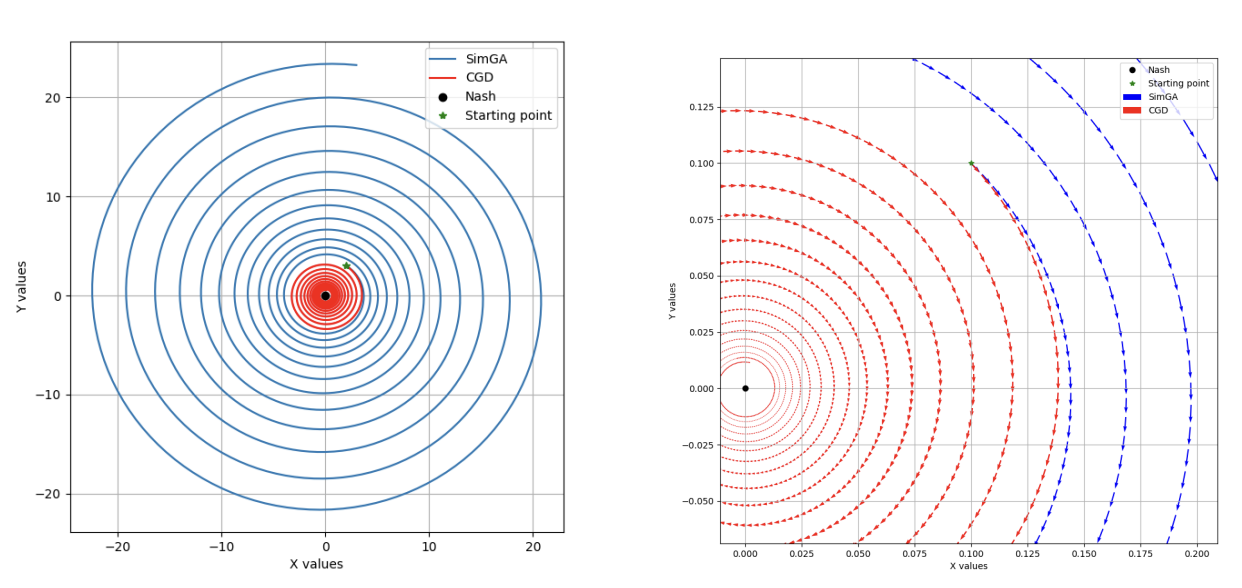
Interactive Robust Policy Optimization for Multi-Agent Reinforcement Learning
Videh Raj Nema, Balaraman Ravindran NeurIPS Deep RL and Strategic-ML workshops, 2021 Paper Addressing non-stationarity and robustness in multi-agent reinforcement learning using principles from game theoretical optimization and adversarial learning, respectively. This work provides practical policy gradient (stochastic and deterministic), natural policy gradient, and trust-region algorithms for multi-agent reinforcement learning using centralized training and decentralized execution. |
|
For more research projects and internships, academics, and extra-curricular, please refer to the CV. |
|
Website template from Jon Barron. |